¥6.80
购买后会显示你购买的服务器的账号和密码。并且发送服务器的账号和密码到你的邮箱作为备份。格式为xxxx:zzzz (以“:”分割,前边是账号,后边是密码),例如 xiaoyun:998899 那么你的服务器的账号和密码分别是xiaoyun和998899。
有了账号和密码后,不会登录服务器的参考链接:http://www.biocloudservice.com/wordpress/?p=292
有问题咨询客服,客服微信:18502195490
描述

代码具体包括:
Step1 输入数据
Step2 构建随机森林模型
Step3 找出使模型准确率达到最优所需要的树的数量
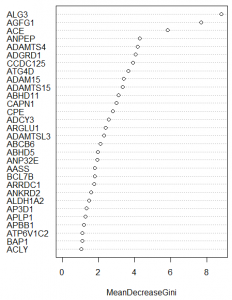
Step4 选择诊断标志物
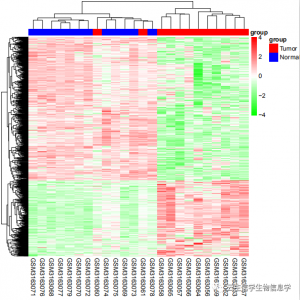
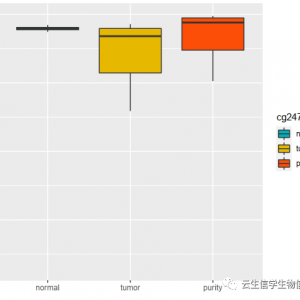
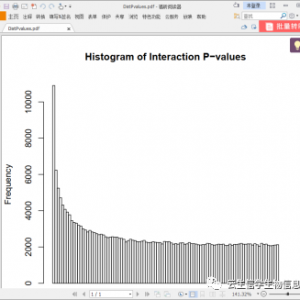
下面是代码中附带数据逐步分析结果: